O que Você Vai Aprender:
- O que é redundância em Data Centers
- O conceito real de alta disponibilidade (HA)
- Como eliminar pontos únicos de falha (SPOF)
- Arquiteturas N, N+1, 2N e 2N+1
- Diferença entre Tier (Uptime) e Grade Level (IDCA)
- Como disponibilidade impacta negócios e economia digital
⏱️ Tempo de leitura: 12–14 minutos
Resumo Executivo
Na economia digital moderna, indisponibilidade não é apenas um problema técnico — é um risco estratégico.
Plataformas digitais, bancos, e-commerce, serviços públicos e aplicações críticas dependem de Data Centers que operam continuamente. Qualquer interrupção pode impactar milhões de usuários e gerar perdas financeiras relevantes.
Nesse cenário, dois conceitos se tornam centrais:
- Redundância: duplicação de componentes críticos
- Alta disponibilidade: capacidade de manter a operação mesmo diante de falhas
👉 Esses conceitos não são opcionais. São estruturais.
O que é Redundância?
Redundância é a prática de replicar componentes essenciais da infraestrutura para garantir continuidade operacional.
Em termos simples:
Se um componente falhar, outro assume imediatamente, sem impacto perceptível.
Essa abordagem se aplica a toda a infraestrutura:
- Sistemas elétricos
- Resfriamento
- Conectividade
- Servidores
- Armazenamento
A redundância não elimina falhas — ela garante que falhas não interrompam o serviço.
O Maior Inimigo – Single Point of Failure (SPOF)
Um dos conceitos mais importantes em arquitetura de Data Centers é o SPOF (Single Point of Failure).
Um SPOF é qualquer componente que, ao falhar, interrompe todo o sistema.
Exemplos comuns incluem:
- Um único UPS
- Um único link de internet
- Um único switch
- Um único sistema de resfriamento
Em ambientes modernos, a existência de um único SPOF é inaceitável.
Exemplo Prático – Quando a Arquitetura Falha
Considere um Data Center com apenas uma linha de alimentação elétrica.
Se houver falha nessa linha:
- Todos os servidores desligam
- Aplicações ficam indisponíveis
- Operações são interrompidas
Agora escale esse cenário:
- milhões de usuários
- sistemas financeiros
- serviços essenciais
O impacto deixa de ser técnico e passa a ser sistêmico.
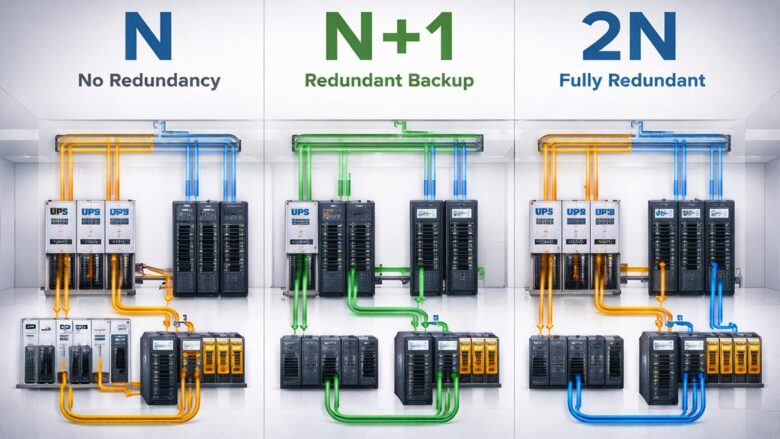
Modelos de Redundância
A redundância é implementada em diferentes níveis, dependendo da criticidade do ambiente.
N — Sem redundância
Apenas a capacidade necessária para operação.
Alto risco operacional.
N+1 — Redundância básica
Um componente adicional de backup.
Exemplo: 3 sistemas necessários + 1 reserva.
✔ Bom equilíbrio entre custo e segurança
2N — Redundância completa
Duplicação total da infraestrutura.
Dois sistemas independentes operando em paralelo.
✔ Alta confiabilidade
❗ Alto custo
2N+1 — Redundância máxima
Duplicação completa + backup adicional.
Usado em ambientes críticos de missão.
Classificação: Uptime vs IDCA
Historicamente, a disponibilidade foi classificada pelo modelo Tier do Uptime Institute:
- Tier I — Básico
- Tier II — Redundância Parcial
- Tier III — Manutenção Sem Parada
- Tier IV — Tolerante a Falhas
No entanto, esse modelo é centrado na infraestrutura física.
Evolução – Grade Levels do IDCA (AE360®)
O modelo AE360® introduz uma abordagem mais ampla:
- G4 — básico
- G3 — redundância limitada
- G2 — arquitetura estruturada
- G1 — alta disponibilidade
- G0 — resiliência total do ecossistema
A principal diferença:
O Uptime mede infraestrutura.
O IDCA mede o ecossistema completo.
Interpretação Estratégica
Enquanto o modelo Tier avalia robustez física, o modelo AE360® avalia:
- integração entre camadas
- comportamento sistêmico
- impacto na aplicação
👉 A disponibilidade deixa de ser local e passa a ser sistêmica.
Como a Redundância Funciona na Prática
Um Data Center moderno utiliza múltiplas camadas de redundância:
- caminhos elétricos independentes
- múltiplos sistemas de resfriamento
- redes com rotas alternativas
- replicação de dados
Tudo projetado para garantir continuidade.
Redundância Elétrica
A energia é o elemento mais crítico.
Estratégias incluem:
- múltiplas fontes de energia
- UPS redundantes
- geradores
- distribuição duplicada
Sem energia, não há operação.
Na prática, a redundância elétrica envolve múltiplos caminhos independentes de fornecimento de energia. Isso pode incluir diferentes subestações, linhas de transmissão distintas e até fornecedores diferentes de energia.
Além disso, sistemas UPS (Uninterruptible Power Supply) são utilizados para garantir continuidade imediata, enquanto geradores entram em operação em caso de falhas prolongadas.
A arquitetura elétrica moderna não apenas garante continuidade, mas também permite manutenção sem interrupção.
Redundância de Cooling
O resfriamento é essencial para estabilidade.
Sem ele:
- equipamentos superaquecem
- performance cai
- falhas ocorrem
Por isso:
- chillers redundantes
- airflow controlado
- sistemas paralelos
Os sistemas de resfriamento também precisam operar com alta redundância, especialmente em ambientes de alta densidade. Isso significa que múltiplos chillers, unidades de precisão e sistemas de distribuição de ar trabalham em paralelo.
Além da redundância física, o controle inteligente de fluxo de ar e a separação entre corredores quente e frio são fundamentais para evitar hotspots e garantir eficiência térmica.
Em ambientes modernos, falhas térmicas são tão críticas quanto falhas elétricas.
Redundância de Rede
A conectividade é igualmente crítica.
Estratégias:
- MMúltiplos Provedores
- Rotas Independentes
- Failover Automático
A redundância de rede vai além de múltiplos provedores. Ela envolve a criação de caminhos independentes de comunicação, com roteamento dinâmico e capacidade de failover automático.
Isso garante que, mesmo em caso de falha de um link ou de um provedor, o tráfego seja redirecionado sem impacto perceptível para o usuário final.
A conectividade contínua é essencial para aplicações distribuídas e serviços em tempo real.
Alta Disponibilidade (HA)
Alta disponibilidade é o resultado da redundância aplicada de forma inteligente.
Objetivo:
Manter sistemas operando continuamente, mesmo diante de falhas.
Redundância vs Resiliência – Qual a Diferença?
Embora frequentemente utilizados como sinônimos, redundância e resiliência são conceitos distintos.
A redundância refere-se à duplicação de componentes, enquanto a resiliência está relacionada à capacidade do sistema de se adaptar e continuar operando diante de falhas.
Um sistema pode ser redundante, mas não resiliente, se não conseguir reagir adequadamente a falhas.
Na prática, Data Centers modernos combinam redundância física com inteligência operacional para alcançar resiliência real.
SLA e Níveis de Disponibilidade
- 99,9% → ~8,7h/ano
- 99,99% → ~52 min
- 99,999% → ~5 min
Pequenas diferenças percentuais representam impactos enormes.
Failover Automático
Quando ocorre falha:
- o sistema detecta
- redireciona
- mantém operação
Sem intervenção humana.
A Importância dos Testes de Failover
Ter uma arquitetura redundante não é suficiente. É fundamental validar continuamente se os mecanismos de failover funcionam conforme esperado.
Testes periódicos permitem identificar falhas ocultas, configurações incorretas e dependências não mapeadas.
Muitos incidentes em Data Centers ocorrem não pela ausência de redundância, mas pela falta de validação prática.
Empresas maduras tratam testes de failover como parte essencial da operação.
Redundância Geográfica
A evolução da disponibilidade é a distribuição.
- multi-site
- multi-region
- disaster recovery
Protege contra falhas regionais.
RTO e RPO
Dois indicadores críticos:
- RTO → Recovery Time Objective (Objetivo de Tempo de Recuperação)
- RPO → Recovery Point Objective (Objetivo de Ponto de Recuperação), perda aceitável de dados
Definem o nível de arquitetura.
Arquitetura distribuída
Hoje, aplicações operam em múltiplos locais simultaneamente.
Isso aumenta resiliência e reduz risco.
Benefícios Estratégicos
- continuidade
- confiabilidade
- escalabilidade
- confiança do cliente
O custo do Downtime
O impacto inclui:
- perdas financeiras
- danos à reputação
- quebra de contratos
Em alguns casos: milhões por minuto.
Impactos reais de indisponibilidade
Grandes incidentes de indisponibilidade já demonstraram o impacto sistêmico de falhas em Data Centers.
Plataformas globais de tecnologia já sofreram interrupções que afetaram milhões de usuários simultaneamente, gerando perdas financeiras significativas e danos à reputação.
Esses eventos reforçam que a alta disponibilidade não é apenas um requisito técnico, mas um fator crítico de negócio.
Redundância como estratégia
Redundância não é custo.
É proteção do negócio.
Empresas maduras tratam como investimento.
Disponibilidade na Era da IA
Com IA:
- Workloads Contínuos
- Alta Densidade
- Maior Sensibilidade
Disponibilidade se torna ainda mais crítica.
O Futuro
- Automação
- IA
- Sistemas Autônomos
- Self-healing
Falhas existirão, mas não causarão interrupções.
Insight Estratégico
Disponibilidade é base da economia digital.
Sem ela:
- Não há escala
- Não há confiança
- Não há crescimento
FAQ
Redundância elimina falhas?
Não. Minimiza impacto.
Todo ambiente precisa 2N?
Não. Depende da criticidade.
Conclusão
Na Economia Digital moderna, a disponibilidade deixou de ser uma característica técnica e passou a ser um requisito fundamental de negócio.
Data Centers sustentam aplicações críticas que impactam diretamente empresas, governos e a sociedade. Qualquer interrupção pode gerar efeitos em cascata, afetando cadeias inteiras de valor.
Por isso, a redundância não deve ser vista como custo, mas como parte essencial da arquitetura estratégica.
O modelo AE360® reforça que a disponibilidade é resultado da integração entre todas as camadas do ecossistema, desde a Topology até a Application.
Sobre o Autor
Wilson Laia é Head of LATAM da International Data Center Authority (IDCA), com mais de 40 anos de experiência em Infraestrutura Digital, Data Centers, Cloud e Transformação Tecnológica. 🔗 https://linkedin.com/in/wilsonlaia
📸 @wlaia